Displaying items by tag: crawling
ParaCrawl - A CEF Digital Success Story
EU funding supports ParaCrawl, the largest collection of language resources for many European languages – significantly improving machine translation quality. Read the Success Story published by CEF Digital, titled "ParaCrawl taps the World Wide Web for language resources".
ParaCrawl corpus release 5
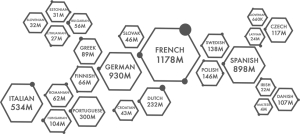
The fifth version of the ParaCrawl corpus has been released. It is the first release under the ParaCrawl action: "Broader Web-Scale Provision of Parallel Corpora for European Languages". The latest release of the corpora contains newly crawled data, including data from Internet Archive. Enhancements in document and sentence aligners with updated BiCleaner strategy resulted in corpora twice the size compare to release v4 for all the official EU languages (23 languages paired with English).
Corpora sizes and download links are available from ParaCrawl's website (https://paracrawl.eu/releases.html).
Following chart shows an overview of the corpora sizes in terms of English word counts: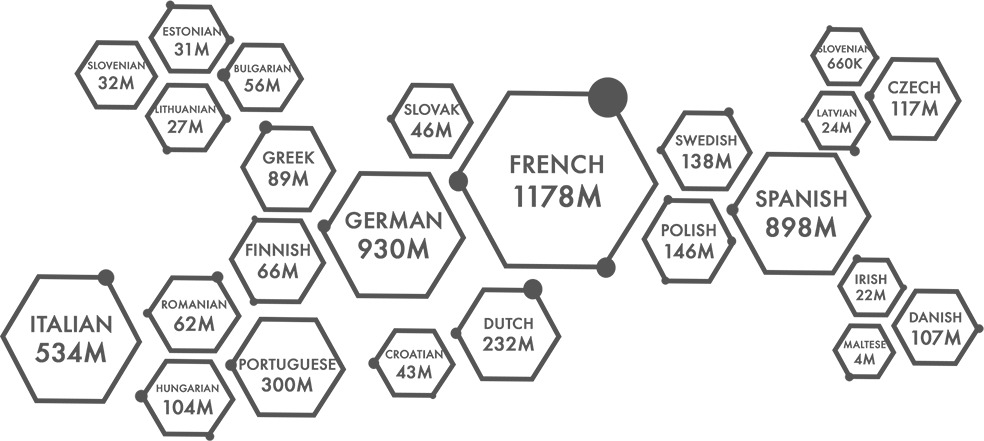
The latest release of the ParaCrawl OpenSource Pipeline (Bitextor) is available on Github.
The ParaCrawl efforts will continue with the Broader Web-Scale Provision of Parallel Corpora for European Languages; focusing on more language pairs, ingesting more file formats beyond HTML, expanding the crawl coverage and applying domain filtering. Stay tuned for more news and follow us on twitter @ParaCrawl.
The corpus and software are released as part of the ParaCrawl project co-financed by the European Union through the Connecting Europe Facility (CEF). This release used an existing toolchain that will be refined throughout the project and expanded to cover all official EU languages (23 languages parallel with English).
The corpora are released under the Creative Commons CC0 license ("no rights reserved"). (https://creativecommons.org/share-your-work/public-domain/cc0/)
Kick-off meeting of ParaCrawl 3: Continued Web-Scale Provision of Parallel Corpora for European Languages

Last week took place the kick off meeting of the third CEF funded Action aiming at improving and expanding the parallel corpora developed in two previous actions (ParaCrawl-1-Action no 2016-EU-IA-0114 and ParaCrawl-2-Action no 2017-EU-IA-0178). These previous Actions have already resulted in the release of the largest ever publicly available parallel corpora, for all EU/EEA official languages paired with English, as well as a complete end-to-end crawling and extraction open-source software toolkit.
ParaCrawl 3 will offer improved extraction software capable of efficiently processing an even larger portion of the Web (more than 1 compressed petabyte). At the same time, it will apply state-of-the-art neural methods to the detection of parallel sentences, and the processing of the extracted corpora. Special emphasis will be placed on collecting larger corpora for language pairs that are currently under-resourced. The corpora will be made more useful for training machine translation (MT) systems by post-processing the data to split long sentences, repair broken sentences and synthesise new sentences.
The new corpus releases will be made available via a data portal which will allow the users building the machine translation systems to select the types of text which best fit their purpose.
Keep posted!